[데이터베이스기본] SELECT 구문 파헤치기

database

데이베이스 시작에 기본이 되는
출력문 SELECT 구문을 사용하기 위해
함께 알아야하는 여러가지 연산자를 알아볼까요?

<테이블 구조 조회>
1) 데이터를 조회할 때 쓰는 것:
SELECT DESCRIBEemployees


<SELECT 구문>
-주요 키워드-
SELECT :출력을 원하는 컬럼(열)을 선택하는 키워드 (부분)
from :테이블명이 나온다(전체)


<null이란 뭘까?>
null 정의
-사용할 수없는 값, 알려지지 않는 값, 할당받지 못한 값,
모르는 값, 아직 정의되지 않은 값,
null 특징
-null은 공백이 아니라 특수한 값이다.
-연산식에 널 값이 하나 생기명 통째로 null 값으로 처리한다
-그래서 최대한 null 값이 안 생기게 한다. 그런 방법은 나중에 배움

<닉네임 사용법_ 컬럼명>
①컬럼명(AS) 닉네임
②컬럼명 (한칸 띄우고) 닉네임
③컬럼명 (AS) "닉네임"
(이때 닉네임은 대소문자 구분, 공백 포함, 특수문자 포함하고 싶을 때 사용)
예> select last_name AS name, commission_pct comm
from employees;


<연결 연산자(||)>
하나의 컬럼에 이어서 표현
예> select last_name||job_id AS "Employees"


<리터럴 문자=상수 표현>
-('') 작은따옴표에 넣어서 표현
-쿼리 구문에 포함된 일반 문자, 숫자, 날짜 값

예>SELECT last_name||'is a'||job_id AS "Employee Details"
결과> Employee Details
Adam is a ST_CLERK
VARGS is a FI_ACCOUNT

<distinct_중복제거>
중복된 값을 자동으로 제거
예>select distinct department_id, job_id(둘 다 만족하는 것)
from employees;

<비교연산자>
같지 않다 (!=,^=, <>)

날짜 데이터의 형식:영국식 날짜-달-연도 (-- --- --)

''을 쓰면 문자열로 인식해서 대소문자를 구별해서 써야 인식함!!!!!

<where(조건절) 알아보기>
select
from
where 조건(칼럼, 연산자, 조건)=>행 제한


<범위연산자>
경계값을 포함한 범위에 해당하는 값을 가진 행을 선택하는 조건
BETWEEN A AND B
(A:하한값 B:상한값)
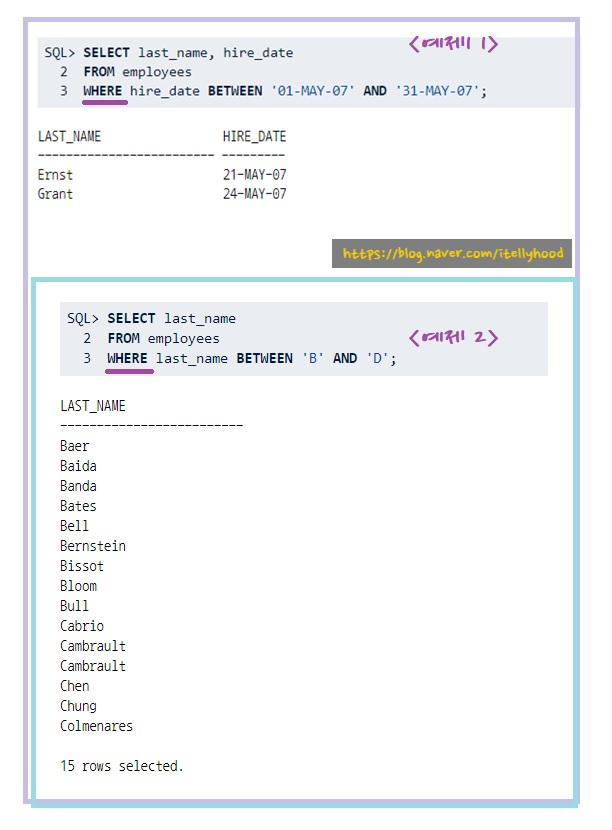

<IN 연산자>
여러 개의 나열된 조건 중 일치하는 값을 가진 행을 선택하는 조건
<예시>


<LIKE 연산자(패턴 연산자)>
LIKE 연산자_ 특징
‘_’ ===>한자리 문자를 나타냄
‘%’ ==>0~자리 문자
LIKE 연산자 형태: like ‘ ’


<논리 조건식>
A and B A 그리고 B
A 조건과 B 조건을 동시에 만족하는 행을 결과로 출력
A or B A 또는 B
A 조건과 B 조건 둘 중 하나 이상의 조건을 만족하는 행을 결과로 출력
AND와 OR을 조합해서 여러 조건식을 달 수 있으나
AND가 OR보다 우선순위가 높기 때문에 이를 고려해서 작성을 한다.
OR이 먼저 연산되어야 하는 경우 괄호를 사용해서 우선순위를 바꿀 수 있다.
NOT
다른 연산자와 조합으로
기존의 연산자와는 반대되는 결과를 내놓는 논리 조건식이다.


<ORDER BY(정렬)>
order by : asc(오름차순)/desc(내림차순)
사용자가 지정한 정렬 기준, 방식으로 결과를 정렬하는 절
정렬 방식을 생략하면 기본값인 오름차순이 적용된다.



ㅣ수고 많으셨어요~ㅣ

부족한 글을 읽어주셔서 감사드립니다
아직 부족한 게 많으니
틀린 곳이 있다면
조언의 말씀 꼭 부탁드립니다!!!!
